
Learn what machine learning is, the various types of machine learning models, and walk through building a machine learning model in Python with this step-by-step guide.

Machine Learning Overview & Types
Machine learning (ML) algorithms can improve their functionality and performance through training on large quantities of data. This capacity makes ML seem like it has “intelligence” because data scientists do not have to explicitly program it to solve for every specific question the algorithm might encounter.
They are taught how to solve and derive patterns from new questions based on statistical models and the previous data used to train the model. There are four main types of ML algorithms used today: supervised learning, unsupervised learning, reinforcement learning, and deep learning. Let’s discuss them.
1. Supervised Learning
Supervised learning algorithms use labeled training data to learn input patterns and wanted output patterns that you can use for new problems. It is called supervised learning because a data scientist expects a certain desired output, and she can adjust the model’s parameters to influence it.

In other words, she is a human supervisor who checks whether the machine is correct or not and makes changes to the algorithm to ensure it produces a correct result. Once it is trained, a data scientist can apply the model to new observations to produce a prediction or classification output.
2. Unsupervised Learning
Imagine you had a massive amount of unlabeled data from a social media website to determine whether a post was made from an authentic user and not a bot. It would take years to label it correctly. What do you do? Unsupervised learning models are used in these types of situations to detect hidden patterns and clusters of similar posts.
These types of models go through an iterative processwithout human supervision to try out different clustering and classifying techniques to get the most optimal results.
3. Reinforcement Learning
Reinforcement learning models use a trial-and-errorapproach where successful decisions to reach an optimal solution are reinforced and inefficient or non-favorable decisions are discarded. It is a behavior learning model where the sequences to get to the best answer are reinforced and favored.
4. Deep Learning
Deep learning is a method in machine learning that is most associated with Artificial Intelligence (AI) because it is designed to emulate how a human brain works. It uses neural networks in successive layers to gain insights into data in an iterative manner. Neural networks can sift patterns from unstructured and highly abstract data. Deep learning is especially well-suited for image and speech recognition as well as computer vision.
What Can I Do with ML?
Machine learning is used in many different industries, ranging from entertainment to national security. The chances are, you have used or encountered a machine learning model but didn’t even notice it. Have you ever used Spotify or Pandora and wondered how it could generate an awesome playlist? There’s a recommendation model behind it, and many dissertations have been written to demystify recommendation engines.
One of my favorite machine learning applications is quite silly, but I think it helps a lot of people become less intimidated by machine learning and artificial intelligence. The app is called “Not Hotdog,” and it was created for a TV show called Silicon Valley. The app works by taking a picture of objects, and it will tell you whether it is a hot dog or not. It’s a silly premise, but it’s worthwhile to study how it was made and even make a clone using instructions found here.
ML Tutorial 101 (Iris Dataset)
Nine out of ten data scientists encountered this dataset from the University of Irvine when they first started out on their data science journey and created different classification algorithms from it. This dataset recorded different features from iris flowers and we’ll be creating three models to classify which irises belong to which species. Let’s join the party, it’s time to code!
1. Import Libraries
We’ll be using a lot of packages from scikit-learn to split and cross-validate our data, import classification models, and measure the accuracy of our predictions.
2. Download the Data
We’ll be using a link to download the data from GitHub and assign column names manually.
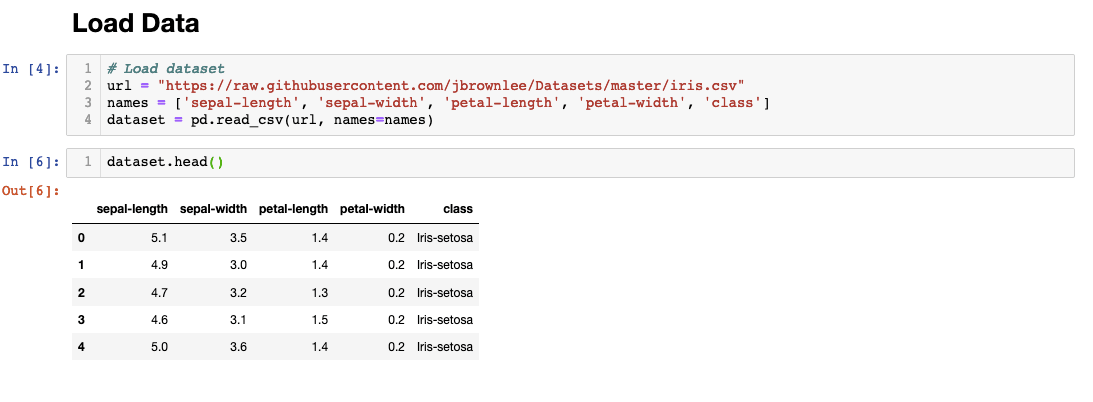
3. Light EDA
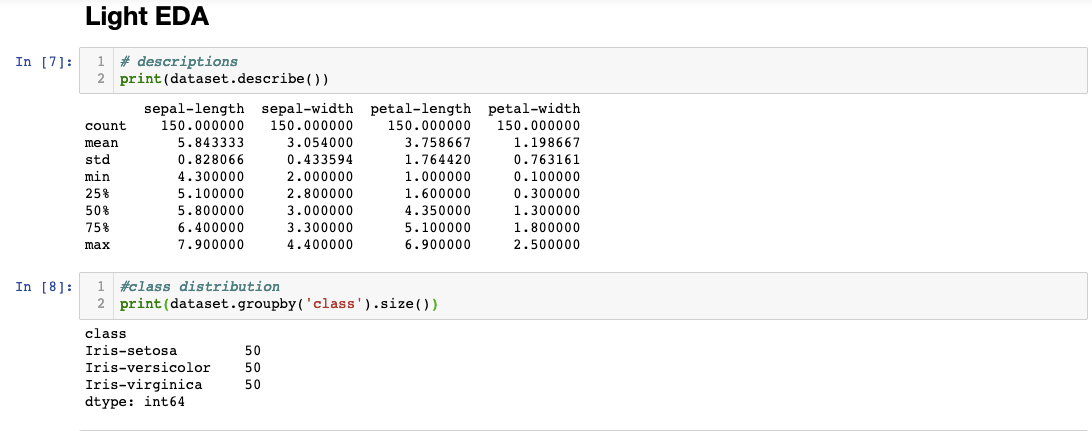
It is important to see the class distribution of your dataset because unbalanced classes can adversely affect your models. Training your models on unbalanced classes can make your models not accurate or too sensitive to one type of class, resulting in a lot of false positives. Feel free to visualize your data using dataset.hist() or dataset.plot(kind = 'box') to see distributions and feature frequencies.
4. Train/Test Split + Training the Models
I’ve created training and validation splits in my data. 80% of the data is used for training and 20% for validating results. Afterward, I’ve trained three models to classify different types of irises:
- Logistic Regression
- KNeighbor Classifier
- Decision Tree Classifier

On line 10, you can see I’ve decided to use accuracy as the determining score for model performance. Different types of model performance metrics could be used depending on the type of question you’re trying to solve but accuracy seemed apt for this exercise.
Finally, on line 13, you can see I’ve printed out the mean of cross-validated model scores and the standard deviation. Since the decision tree classifier performed the best, I’ll use that to demonstrate predicting it against the validation data we’ve been holding out.
5. Validation
I’ve created a variable named ‘model’ and assigned Decision Tree Classifier as the value. I’ve trained it on line two and predicted it against the test/validation dataset I’ve been withholding.
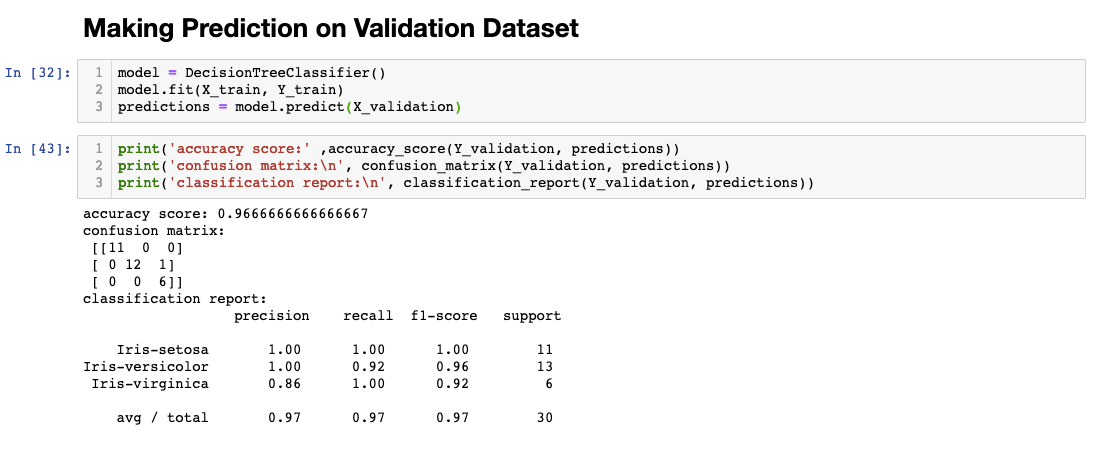
You can see that it reached a 96% accuracy rate. I’ve also included a confusion matrix and classification report for completeness. I won’t describe how to read it in this article because it is outside the scope, but you can read more about it here.
Congrats on completing your first data science project!


